Algorithmen-Entwicklung

Individuelle Algorithmen für Ihre Anwendung
Wir sind spezialisiert auf die Erforschung und Entwicklung von Algorithmen zur Lösung komplexer mathematischer Probleme, wie sie bei der Sensorfusion oder automatische Datenanalyse notwendig sind. Hierbei spielen Verfahren eine große Rolle, mit denen Sensordaten, die auch Störungen unterliegen können, zuverlässig verarbeitet werden können.
Unser Alleinstellungsmerkmal ist die umfassende Kompetenz und langjährige Erfahrung im Bereich der Sensorfusion, der automatischen Datenanalyse und der Entwicklung qualitativ hochwertiger Software für verschiedene technische Bereiche. Hierbei spielt neben der Integration der entwickelten Algorithmen auch Sicherheits- und Qualitätsaspekte bei der Entwicklung eine große Rolle.
Anwendungsspektrum
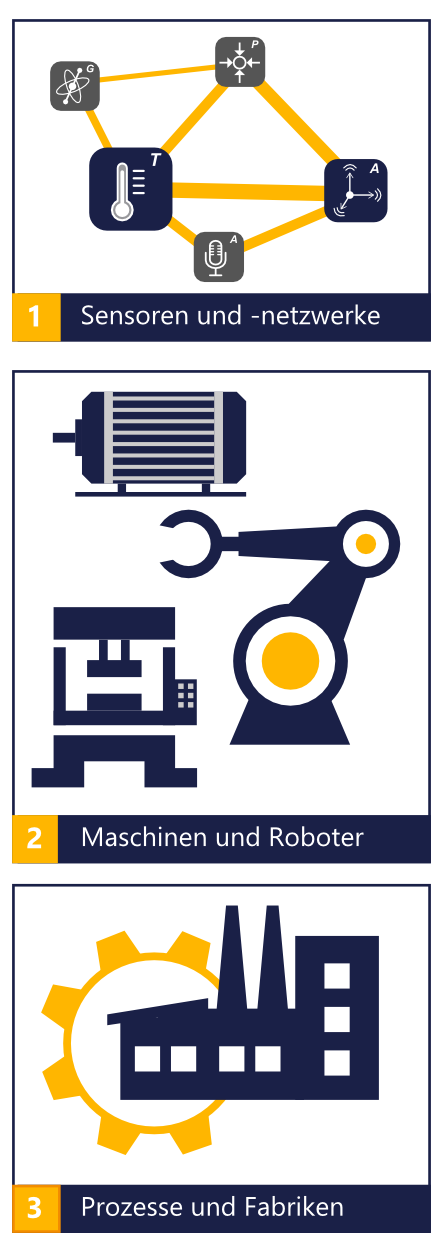
Überall wo es darauf ankommt Information, Wissen und letztendlich Mehrwert aus den Sensor- und Maschinendaten zu extrahieren sind Algorithmen für die Verarbeitung der Daten notwendig. Dabei reicht das Spektrum von den einzelnen Sensoren über Netzwerke von Sensoren bis hin zu Geräten und Maschinen und letztendlich ganze Prozesse und intelligente Fabriken. Die vorhanden Daten, gewünschte Information und vorhandenen Randbedingung sind für jede einzelne Anwendung sehr unterschiedlich – für diese unterschiedlichsten Anwendungen gilt es die optimalsten Algorithmen herauszufinden und somit den meisten Mehrwert für unsere Kunden zu bieten. Dadurch ergibt sich folgender Nutzen:
Die von uns eingesetzten und entwickelten Algorithmen besitzen ein sehr breites Anwendungsspektrum im Bereich der Überwachung von Maschinen, Anlagen und Prozessen – von der Detektion von Anomalien bis zur komplexen Fehlerdiagnose und der sofortigen Einleitung der Störungsbeseitigung. Es können Vibration und Geräusche sowie andere Betriebsbedingungen von diversen industriellen Maschinen und Anlagen überwacht werden. Dies ist nur möglich mit einem intelligenten Messsystem mit beispielsweise integrierten Mikrofon, Beschleunigungs-, Magnetfeld- und Temperatursensoren und den für die Verarbeitung der Sensordaten notwendigen Algorithmen.
Durch die Kombination verschiedener Sensorsysteme mit den entsprechenden Algorithmen können Prozesszustände, Lager- oder Rotor- und Statorschäden, Ausfall der Steuerungselektronik und auch unbekannte Veränderungen des Systemverhaltens automatisch erkannt werden. Ist ein Vorhersagemodell von bestimmten Schäden vorhanden, können diese sogar prädiziert werden. Somit kann frühzeitig mittels Wartungsmaßnahmen reagiert werden und dadurch können unnötige Schadensausfälle vermieden werden. Falls kein Vorhersagemodell existiert können datengetriebene Algorithmen helfen, das Verhalten von Maschinen sukzessive zu erlernen und im Lauf der Zeit ein umfangreicheres Modell für die prädiktive Instandhaltung herzuleiten. Des Weiteren können die Algorithmen für die Optimierung der komplexen Herstellungsverfahren eingesetzt werden, um eine höhere Ausbeute bzw. eine bessere Produktqualität zu erzielen.
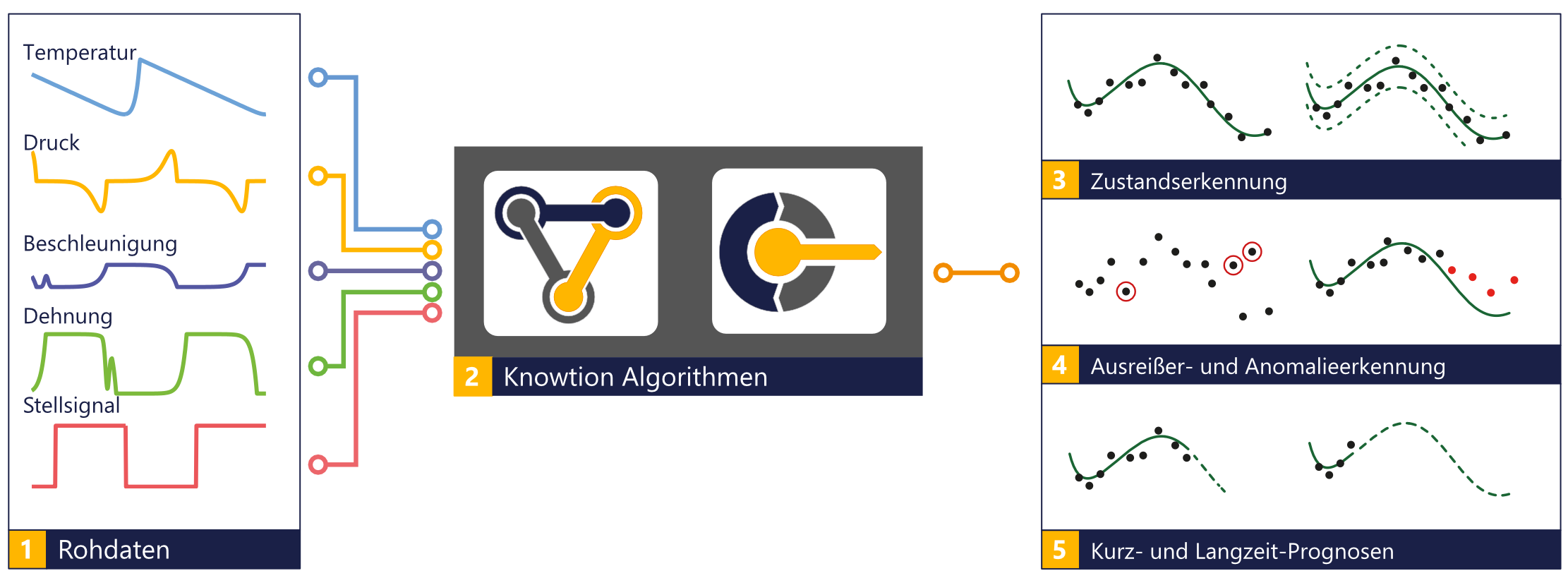
Algorithmen für Sensorfusion
Der Begriff Sensorfusion bezeichnet die Kombination und Aggregation von Messungen mit mehreren Sensoren zu einem stimmigen Gesamtbild. Indem verschiedene Sensorarten zu einem neuen virtuellen Sensor verschmelzen, lassen sich real nicht erhobene Daten berechnen.
Bei der Sensorfusion werden meist modellbasierte Algorithmen gewählt. Diese gehen davon aus, dass physikalisches Hintergrundwissen in Form einer mathematischen Beschreibung vorhanden ist. Dabei werden die Sensordaten mit dieser Information kombiniert, um dadurch ein genaueres Ergebnis der gewünschten Information zu bekommen. Als bekannteste Vertreter seien hier beispielhaft das Kalman Filter (KF) für lineare Systeme und Unscented Kalman Filter (UKF), Extended Kalman Filter (EKF) oder Partikelfilter (PF) für nichtlineare Systeme genannt. Die Wahl des Filters hängt sehr stark von der jeweiligen Anwendung ab.
Die Verknüpfung durch mathematische Modelle schafft so einen Mehrwert durch zusätzliches Wissen aufgrund von Zusammenhängen und Korrelationen. Dabei können auch Investitionskostenvorteile entstehen, da das konsolidierte Gesamtergebnis mehrerer kostengünstigerer Sensoren gleichwertig oder besser sein kann, als die Auswertung weniger, dafür aber hochpräziser oder teurer Spezialsensoren.
Anwendung Advanced Analytics: Sensorfusion
Klicken Sie hier um unser Webinar über Sensorfusion anzusehen.

Algorithmen für Datenanalyse
Bei der automatischen Datenanalyse werden Sensordaten automatisch überwacht und mithilfe mathematischer Algorithmen Abweichungen erkannt. Dazu werden meist große Mengen an Messdaten kontinuierlich bewertet und interpretiert (Big Data), Muster und Abweichungen identifiziert und gegebenenfalls automatisch korrigiert.
Da in den meisten Fälle lediglich Daten vorhanden sind und kein Hintergrundwissen, welches in Form von mathematischen Gleichungen beschreibbar wäre, müssen sogenannte datengetriebene Algorithmen gewählt werden. Diese Algorithmen extrahieren die gewünschte Information direkt aus den Daten. Hierzu zählen das gesamte Spektrum an Methoden aus dem maschinellen Lernen, wie beispielsweise Lineare Regression, Neuronale Netze, Random Forest oder Hidden Markov Modelle.
Anwendung Machine Learning: Anomalieerkennung
Klicken Sie hier um unser Webinar über Anomalieerkennung anzusehen.

Local | Edge | Cloud Software
von Lokal über Edge bis in die Cloud
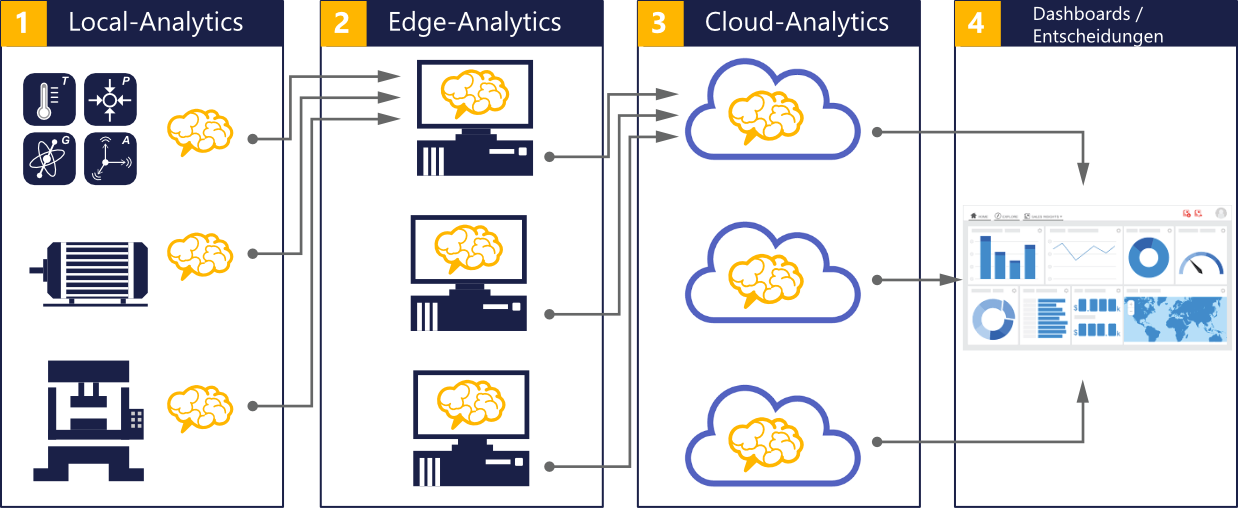
Die gesamte Datenverarbeitungskette mit all den Algorithmen, die in jedem einzelnen Schritt notwendig sind, müssen so umgesetzt werden, dass ein möglichst hoher Mehrwert generiert werden kann. Die Umsetzung erfolgt in der Regel auf der gesamten Ebene – vom kleinen Sensor mit eingeschränkten Rechenressourcen, über Gateways und Edge‐Computern bis hin zu großen Cloud‐Rechnern. Dabei ist klar, dass die Algorithmen nicht einzig auf einer Ebene implementiert sein sollten.
Vielmehr ist es in den meisten Fällen vorteilhafter, die Algorithmen möglichst nahe am Sensor zu implementieren. Dadurch wird eine möglichst frühe Verdichtung und Veredlung der Daten erreicht, und es reduziert die Kommunikations‐ und Speicherkosten. Durch die frühzeitige Extraktion der wesentlichen Information aus den Daten, ist außerdem die Entwicklung von globalen Algorithmen auf den höheren Ebenen weniger komplex. Um die Daten nicht unnötig zu speichern und dadurch hohe Datentransfer‐ und Speicherkosten zu verursachen, bieten sich in den meisten Fälle auch Algorithmen aus dem Streaming‐Analytics Bereich an. Diese Algorithmen verwenden jeden Datenpunkt nur einmal, d.h., die gesamte Information wird direkt heraus extrahiert und die Daten brauchen nicht gespeichert zu werden.
Die genaue Aufteilung der Algorithmen auf Embedded-, Edge- und Cloud-Processing leitet sich von der konkreten Anwendung, insbesondere von dem geforderten Grad an Genauigkeit und Aktualität der Daten, ab. Grundlegend ist das Ziel, das gewünschte Ergebnis mit einem unter wirtschaftlichen und qualitativen Kriterien optimalen Verhältnis von lokaler und globaler Datenverarbeitung zu erreichen. So ist beispielsweise bei der Bilderkennung oder hochfrequente Beschleunigungsdaten Embedded und Edge-Processing der beste Weg, da nur im Fall von Anomalien, Abweichungen und Veränderungen eine Datenübertragung angestoßen wird. Im Falle batteriebetriebener Gateways kann durch solch einen Ansatz Bandbreite und Energie gespart werden.
Unser Vorgehen bei der Entwicklung
Bei komplexen technischen und mathematischen Problemen ist die Entwicklung leistungsfähiger Algorithmen besonders herausfordernd. Um für unsere Kunden eine schnelle und effiziente Algorithmen-Entwicklung zu ermöglichen, verwenden wir einen speziellen, agilen Entwicklungsprozess: