Connect easily with ShiraTech-Knowtion in your area!
Click on a yellow dot to schedule an appointment with your individual contact person right away.




In workshops, we jointly develop initial ideas, approaches and solutions. Application scenarios are specified and analyzed for their potential. A first look at the data and a quick test of our algorithms is performed. If there is enough potential and the prototypical algorithms prove to be promising, the ``algorithm development`` continues.
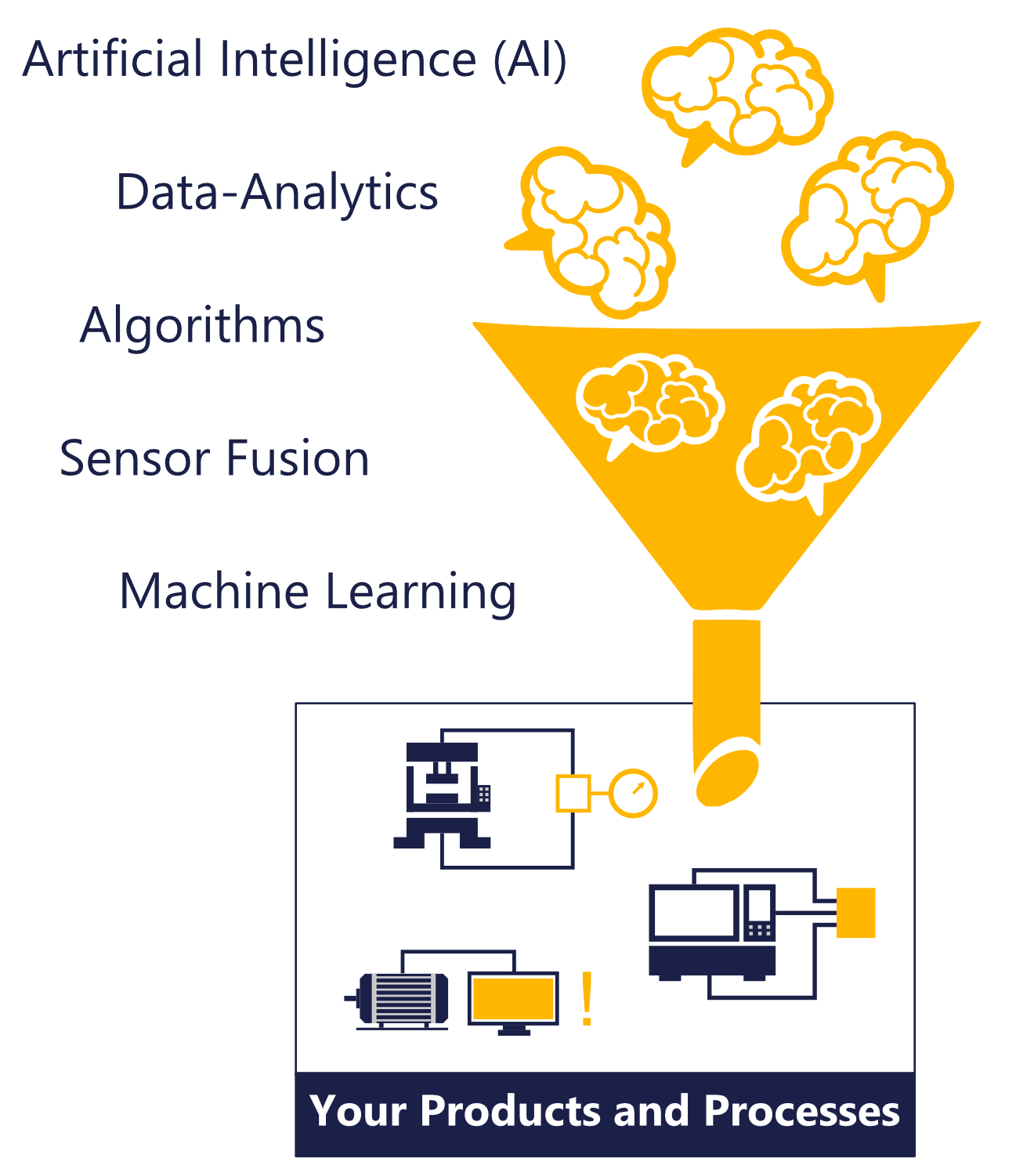
The entire algorithm pipeline is developed and optimized for the specific application. The solutions are in different areas of data science, such as sensor fusion, state estimation, machine learning, state and anomaly detection. We also work with Big Data methods and build predictive models, for example for predictive maintenance. The developed algorithms can then be implemented into existing as well as new software products as needed during the``software development`` stage.
Implementation and integration of the most suitable algorithms for your application. Development of all software modules along the entire processing chain (embedded, edge, cloud). Integration into your processes and infrastructure or development of a completely new standalone software. If you wish, implementation and integration into your cloud or a cloud provider of your choice.

Our pioneering projects in the field of embedded software development create enhanced value for industrial and safety-critical applications. Discover the future of Embedded AI with us – where embedded meets performance.

The development of safety-critical software for aviation according to the highest industry standards has been our core business since 2011. Join us to explore our innovative approaches in this field at ILA 2024.

Predicting manufacturing failures is our passion. For both complex and standardized machines through customized software solutions. Discover your potential for predictive maintenance with us at AMB 2024.

PREDICTO was born at the SPS 2022 and is looking forward to revisiting its cradle. Get to know our all-in-one predictive maintenance solution and say goodbye to unexpected downtimes in your production line.