Algorithm Development

Algorithms for your specific application
We are specialized in research and development of algorithms for solving complex mathematical problems, such as those required for sensor fusion or automatic data analysis. Here, algorithms that are able to process noisy and disturbed sensor data in a robust manner play an important role.
Our unique selling point is our extensive competence and many years of experience in the field of sensor fusion, automatic data analysis and the development of high quality software for various technical areas. In addition to the integration of the developed algorithms, security and quality aspects also play a major role in the development.
Range of applications
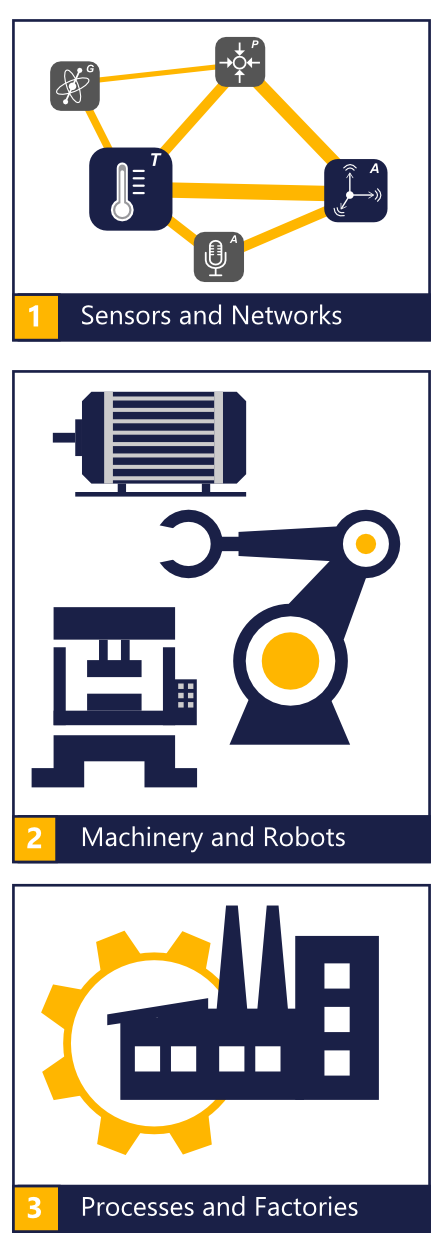
Algorithms for data processing are necessary wherever it is important to extract information, knowledge and ultimately added value from the sensor and machine data. The spectrum ranges from individual sensors through networks of sensors to devices and machines and ultimately entire processes and intelligent factories. The available data, required information and existing boundary conditions are very different for each individual application – for these different applications it is important to find the most optimal algorithms and thus to offer the most added value for our customers. This results in the following benefits:
The algorithms used and developed by us have a very wide range of applications in the area of monitoring machines, systems and processes – from the detection of anomalies to complex fault diagnosis and the immediate initiation of troubleshooting. Vibration and noise as well as other operating conditions of various industrial machines and systems can be monitored. This is only possible with an intelligent measuring system with, for example, an integrated microphone, acceleration, magnetic field and temperature sensors and the algorithms necessary for processing the sensor data.
By combining different sensor systems with the appropriate algorithms, process states, bearing or rotor and stator damage, failure of the control electronics and also unknown changes in system behavior can be automatically detected. If there is a prediction model for certain types of damage, these can even be predicted. In this way, it is possible to react early by means of maintenance measures and thereby avoid unnecessary damage failures. If there is no prediction model, data-driven algorithms can help to gradually learn the behavior of machines and to derive a more comprehensive model for predictive maintenance over time. Furthermore, the algorithms can be used to optimize the complex manufacturing processes in order to achieve a higher yield or better product quality.
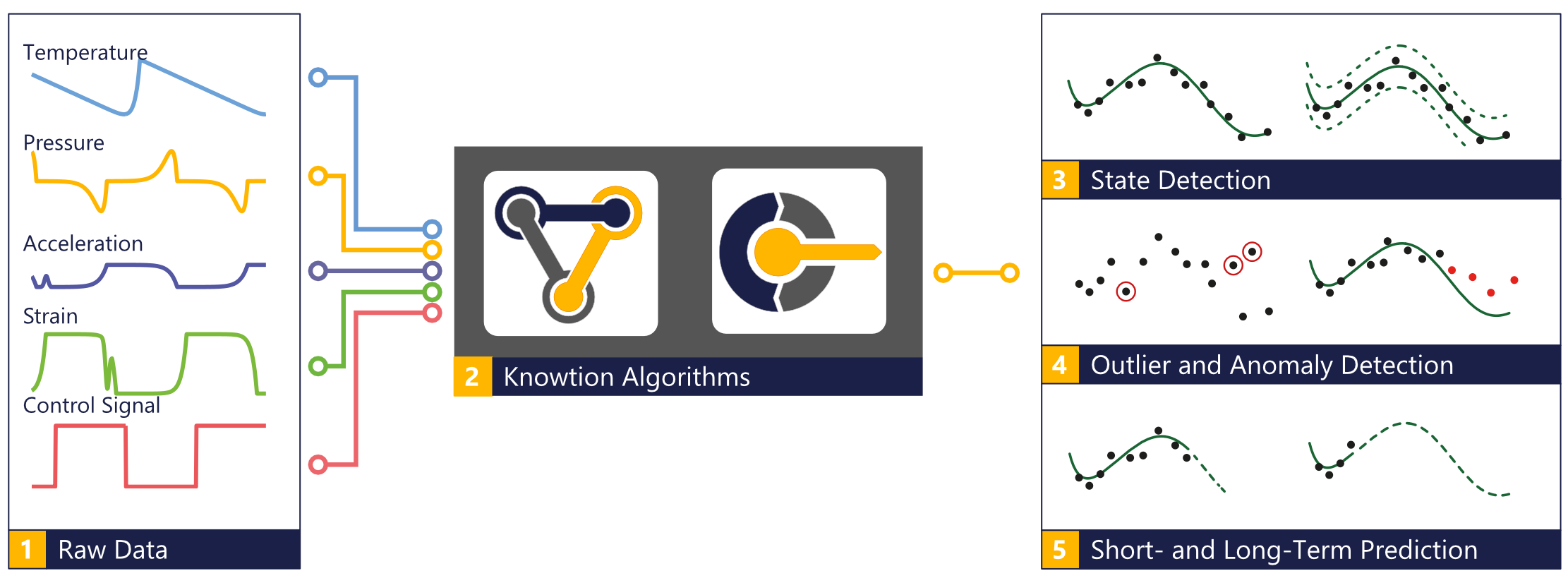
Algorithms for sensor fusion
Sensor fusion is the combination and aggregation of measurements with several sensors to form a coherent overall picture. By merging different types of sensors into a new virtual sensor, data that have not actually been collected can be calculated.
Model-based algorithms are usually chosen for sensor fusion. These assume that physical background knowledge is available in the form of a mathematical description. The sensor data are combined with this information in order to obtain a more precise result of the desired information. The best-known representatives are the Kalman filter (KF) for linear systems and Unscented Kalman Filter (UKF), Extended Kalman Filter (EKF) or particle filter (PF) for non-linear systems. The choice of filter depends very much on the respective application.
The combination with mathematical models creates added value through additional knowledge based on connections and correlations. This can also result in investment cost advantages, since the consolidated overall result of several less expensive sensors can be equivalent or better than the evaluation of fewer, but highly precise or expensive special sensors.
Application of advanced analytics: sensor fusion
Click here to watch our webinar on sensor fusion.

Algorithms for data-analytics
With automatic data analysis, sensor data is automatically monitored and deviations are detected using mathematical algorithms. For this purpose, large amounts of measurement data are usually continuously evaluated and interpreted (big data), patterns and deviations are identified and, if necessary, automatically corrected.
Since in most cases only data is available and no background knowledge that could be described in the form of mathematical equations, so-called data-driven algorithms must be selected. These algorithms extract the required information directly from the data. This includes the entire spectrum of methods from machine learning, such as linear regression, neural networks, random forest or hidden Markov models.
Application machine learning: anomaly detection
Click here to watch our anomaly detection webinar.

Local | Edge | Cloud Software
from local to edge to the cloud
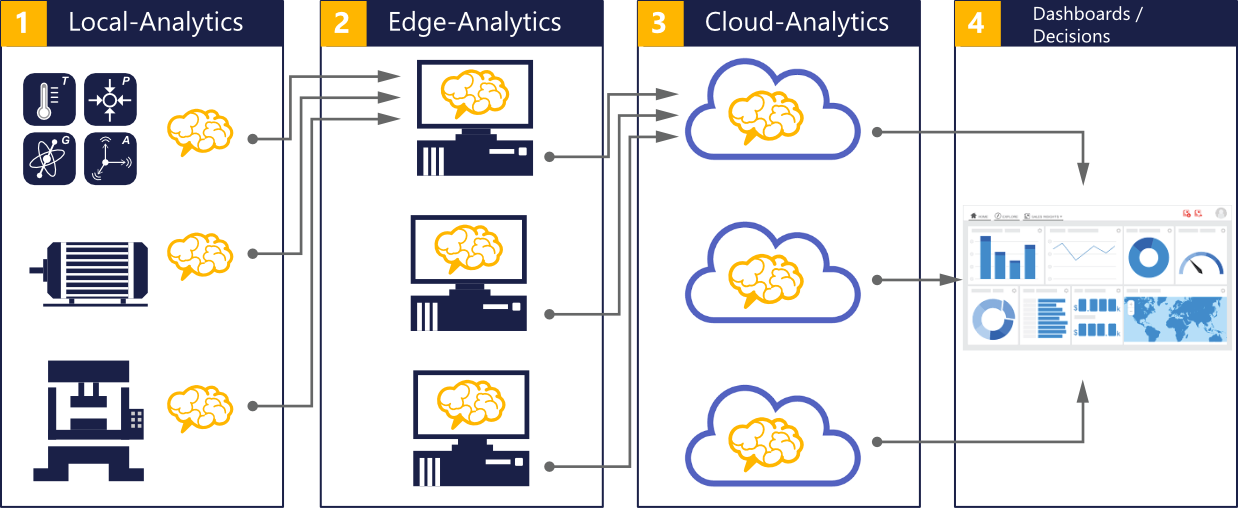
The entire data processing chain with all the algorithms that are necessary in each individual step must be implemented in such a way that the highest possible added value can be generated. The implementation usually takes place on the entire level – from small sensors with limited computing resources to gateways and edge computers to large cloud computers. It is clear that the algorithms should not only be implemented on one level.
Rather, in most cases it is more advantageous to implement the algorithms as close as possible to the sensor. This enables the data to be compressed and refined as early as possible, and it reduces communication and storage costs. Due to the early extraction of the essential information from the data, the development of global algorithms at the higher levels is also less complex. In order not to save the data unnecessarily and thereby cause high data transfer and storage costs, algorithms from the streaming analytics area are also available in most cases. These algorithms only use each data point once, i.e. all information is extracted directly from it and the data does not need to be saved.
The exact division of the algorithms into embedded, edge and cloud processing is derived from the specific application, in particular from the required degree of accuracy and timeliness of the data. The fundamental aim is to achieve the desired result with an optimal ratio of local and global data processing under economic and qualitative criteria. For example, when it comes to image recognition or high-frequency acceleration data, embedded and edge processing is the best way, since data transmission is only initiated in the event of anomalies, deviations and changes. In the case of battery-operated gateways, such an approach can save bandwidth and energy.
Our algorithm development process
The development of powerful algorithms is particularly challenging for complex technical and mathematical problems. In order to enable fast and efficient algorithm development for our customers, we use a special, agile development process:
Thanks to the easy change between the development and evaluation phase and the use of a rapid prototyping environment (according to your requirements, Matlab, Python or R), we are able to develop powerful algorithms for our customers quickly and efficiently. This shortens the development time and reduces costs.